Table of contents
As more and more data is generated and collected, machine learning has become an essential tool for extracting insights and knowledge from this data. However, traditional machine learning methods rely on centralized data storage and processing, which can be difficult to implement in certain scenarios. Federated learning is a relatively new machine learning approach that addresses some of these challenges by allowing multiple parties to collaboratively train machine learning models while keeping their data private.
What is Federated Learning?
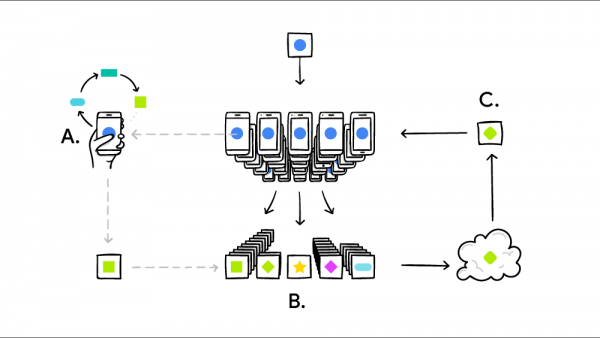
Federated learning is a distributed machine learning technique that enables multiple parties to collaboratively train a machine learning model without sharing their data. In federated learning, the training data is distributed across multiple devices or locations, and the machine learning model is trained on each device locally. The model is then updated with the local training results, and the updated model is sent back to a central server. This process is repeated iteratively until the model is sufficiently accurate.
Federated learning enables organizations to leverage the collective intelligence of a large number of devices or locations while keeping their data private. This approach is particularly useful in scenarios where data privacy is critical, such as healthcare, finance, and other sensitive industries.
How does Federated Learning work?
The process of federated learning can be broken down into three main stages:
1- Initialization: The central server initializes the machine learning model and sends it to the participating devices or locations.
2- Local Training: Each device or location trains the machine learning model on its local data. The local training process is typically done using stochastic gradient descent, which involves randomly selecting a subset of the data for each iteration of the training process.
3- Aggregation: The updated model parameters from each device or location are sent back to the central server, where they are aggregated to form a new global model. This global model is then sent back to the participating devices or locations for further local training.
Benefits of Federated Learning
1- Privacy: One of the most significant benefits of Federated Learning is privacy. Traditional machine learning requires that data be collected and stored in a central location. This creates a significant risk of data breaches, and can also raise concerns about privacy. Federated Learning addresses these issues by keeping the data on the devices that generate it, protecting the privacy of users.
2- Efficiency: Federated Learning is also more efficient than traditional machine learning. Because the data is stored on devices, the need for data transfer is reduced. This means that Federated Learning can be used in situations where bandwidth is limited or expensive, such as in remote locations or on mobile devices.
3- Flexibility: Federated Learning is also highly flexible. It can be used in a wide range of applications, including image and speech recognition, natural language processing, and more. Additionally, because it is designed to work with distributed data, it can be used in situations where traditional machine learning is not feasible.
4- Cost-effectiveness: Federated Learning can also be cost-effective. Because it eliminates the need for data transfer and storage, it can reduce the costs associated with traditional machine learning. Additionally, because it can be used in situations where traditional machine learning is not feasible, it can help organizations to achieve their goals without the need for expensive hardware or infrastructure.
5- Improved accuracy: Finally, Federated Learning can lead to improved accuracy. Because it can be used with distributed data, it can help to address the issue of data bias, which can lead to inaccurate results. By training models on data from a wide range of sources, Federated Learning can help to ensure that models are more accurate and reliable.
Code Example
Here's a basic Python code example for Federated Learning using PySyft library:
First, install PySyft:
!pip install syft
Then, we can create a simple example of Federated Learning where we train a model on multiple remote devices using Federated averaging.
import torch
import syft as sy
from torch import nn, optim
# define the hook to allow PySyft to communicate with other machines
hook = sy.TorchHook(torch)
# define the clients (or virtual workers) that will participate in the Federated Learning
client1 = sy.VirtualWorker(hook, id='client1')
client2 = sy.VirtualWorker(hook, id='client2')
# define the data that will be used for training
data = torch.tensor([[0, 0], [0, 1], [1, 0], [1, 1.]], requires_grad=True)
target = torch.tensor([[0], [0], [1], [1.]], requires_grad=True)
# split the data into two parts, one for each client
data1 = data[:2].send(client1)
target1 = target[:2].send(client1)
data2 = data[2:].send(client2)
target2 = target[2:].send(client2)
# define the model
model = nn.Linear(2, 1)
# define the optimizer and loss function
optimizer = optim.SGD(params=model.parameters(), lr=0.1)
criterion = nn.MSELoss()
# train the model using Federated Learning
for epoch in range(10):
# send the model to the clients
model = model.send(client1)
model = model.send(client2)
# perform local training on each client
optimizer.zero_grad()
pred1 = model(data1)
loss1 = criterion(pred1, target1)
loss1.backward()
optimizer.step()
optimizer.zero_grad()
pred2 = model(data2)
loss2 = criterion(pred2, target2)
loss2.backward()
optimizer.step()
# get the updated model from each client and perform Federated averaging
model = model.get()
model = model.get()
with torch.no_grad():
model.weight.set_((model.weight.get() + model.weight.get()) / 2)
model.bias.set_((model.bias.get() + model.bias.get()) / 2)
print('Epoch:', epoch, 'Loss:', criterion(model(data), target))
In this example, we split the data into two parts and assigned each part to a different client. Then, we trained the model locally on each client and sent the updated model back to the server for Federated averaging. Finally, we printed the loss for each epoch to monitor the progress of the training.
Conclusion
In conclusion, Federated Learning is a promising approach that has the potential to revolutionize the way we approach machine learning in a privacy-preserving and decentralized manner. By enabling models to be trained on distributed devices, Federated Learning allows organizations to leverage data that would otherwise be inaccessible due to privacy or regulatory concerns. The technology is still in its early stages, but its potential applications are vast and varied. As Federated Learning continues to evolve, we can expect to see it become more widely adopted across industries and use cases.